
How to Leverage Data as an AI Chokepoint
A Rough Typology of How to Think About Data as an Asset.

TL;DR: When policy docs say “leverage data”, usually they miss the big questions:
What are you optimising for? Data as leverage for frontier access, for building domestic comparative advantage, or driving open science all require completely different datasets. . Most policy docs don’t differentiate what we’re actually building datasets for.
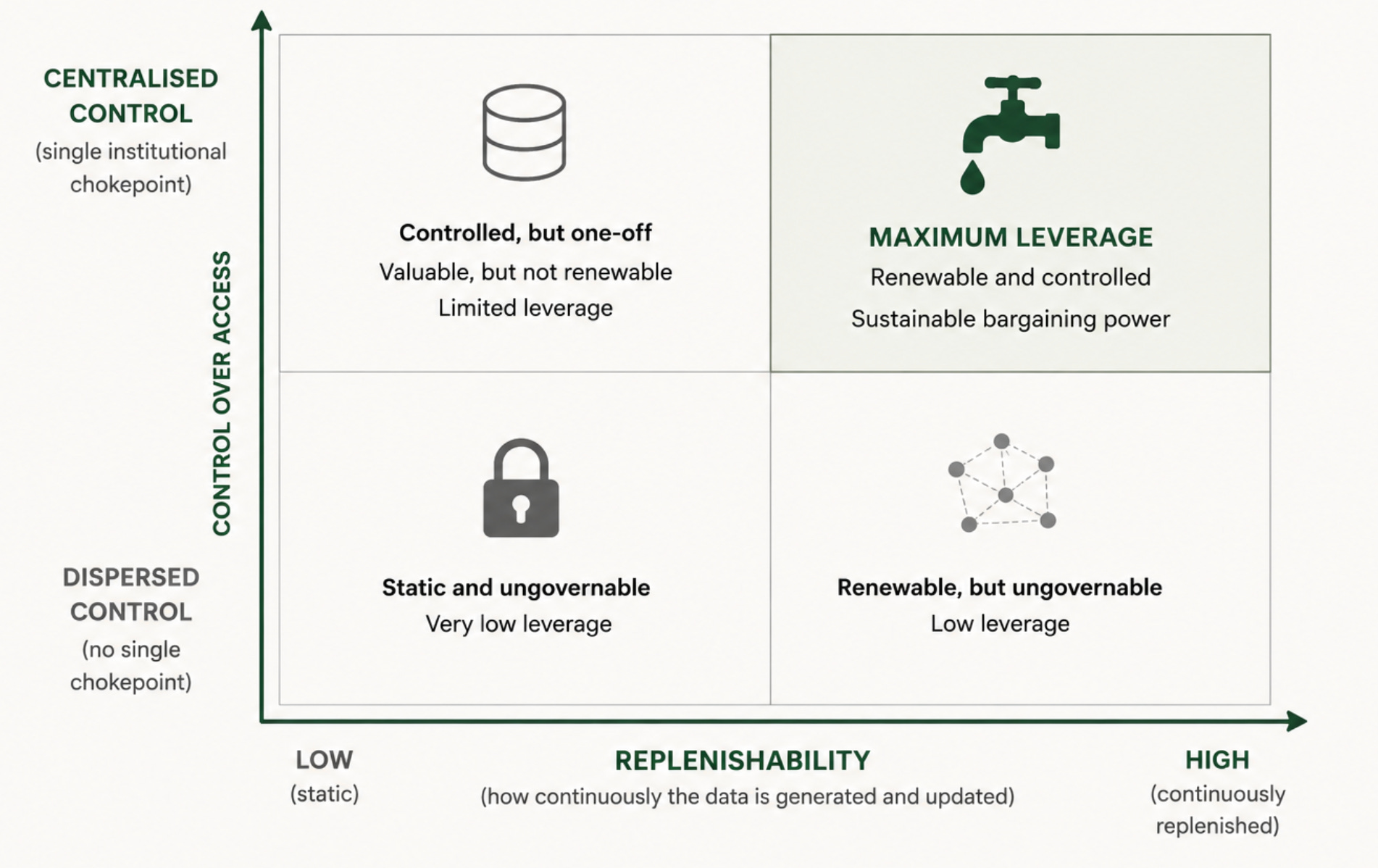
Not all data has durable leverage. A one-off stock dataset (i.e. one of transfer) exhausts its leverage the moment the training run ends. Replenishable flows — where partners must keep coming back — create a much stronger chokepoint.
You need institutional control. Generic IoT data is continuously refreshed but scattered across thousands of firms. No single institution can enforce terms. Leverage requires both renewability and structural control.
There’s often a direct tension between usefulness and ‘leverageability’. Some of the most powerful datasets are often global collaborative ones that no single nation controls — the Protein Data Bank being the obvious case. The datasets that are most “ownable” are often less universally useful. Most national AI strategies ignore this. But there very few national datasets that are universally useful.
Where in the stack matters. If you’re trading national datasets for frontier AI model access, pre-training is the worst part of the stack to be doing that for — because the knowledge is then baked into the weights and leverage gone. RAG and deployment data are far better because the dependency is recreated.
Introduction
“AI sovereignty” has become the foreign policy question of the moment. For middle powers – countries that lack the compute and capital to compete at the frontier – the questions around frontier access will only become harder as Mythos-level models improve and the U.S. increasingly securitises their release.
The key question then becomes: if you can’t build your own frontier models, how else can you create sufficient leverage elsewhere in the AI value chain to have bargaining chips for access – and to create a downstream comparative advantage of one’s own?
While responses to this question proliferate and vary, there is one answer that comes up a lot: data.
The argument goes like this: “Unless you are a true ‘AGI’ believer, AI systems will only be as powerful and useful as the datasets they are trained on. And the most useful applications – whether in AI for science, healthcare, manufacturing automation, AI for defence – will demand ever better and more specific datasets. Middle powers may be sitting on such data assets; ergo, they have something to trade.”
However, most policy documents that argue for middle powers to “leverage data” are evasively vague. What does it really mean to ‘leverage’ data? Build a dataset and just sell it? Beyond the rather vague umbrella term of “data”, what types of datasets are actually the most leverage-able?
What follows is my attempt to lay out some scattered thoughts on what sort of data middle powers should be focusing on – if indeed the aim is leverage for access to frontier AI.
Two dimensions that determine the leverageability of data
Not all data is created equal from a “chokepoint” perspective. Of course, that might not always be a policymaker’s primary concern. Some scientific datasets, for example, may not provide a national “moat” but do offer a different value: for example accelerating open science and driving international collaboration (how very 2000s…).
But when we are talking about data that is conducive to build national moats, comparative advantage, bargaining power, a stake in the AI stack, ‘chokepoints’ – whatever you wish to call it – there are two broad dimensions which determine ‘leverageability’:
Stock versus Flow: A stock is a static corpus that exists – is compiled and then can be transferred. Think a genomic dataset, or a satellite image archive. As some have already pointed out, the issue with stocks is that they are depletable. Once you have been paid by a frontier lab for them to train a model on your static corpus, the knowledge is baked into the weights and you no longer have leverage. Whatever one negotiated at the point of transfer is all the leverage that asset will generate. A flow is different. This is data that is continuously generated and updated because it is connected to real time inputs that keep changing and collecting more data. The question of access becomes a continuous one rather than a one-off. So partners cannot bank a flow of data, they must keep engaging – which means you as a middle power retain a lever.
Structural / institutional control: Yet having a replenishable flow of data is not sufficient. You can have a highly renewable data flow and still have no leverage if there is no governance mechanism or institutional chokepoint through which access must pass. Generic IoT (Internet of Things) data, for instance, may be continuously refreshed and valuable – but if it is dispersed across thousands of individual private firms with no national aggregation architecture, no one can enforce the terms.
Data 2x2: Replenishable + Single Point of Control = Highest Leverage

Only the combination of these two things – a continuously renewed data stream and a single institutional point of control – can create durable bargaining power. Yet this combination is far rarer than most policy papers that spam the “leverage data” recommendation assume.
And there are three other additions worth mentioning:
1. Annotation as a moat. Raw data is less valuable than labelled data because that way expertise and tacit knowledge become a part of the asset.
2. Context dependency. This is closely tied to the replenishability of the dataset but slightly different. Generic sensory data (e.g. in advanced manufacturing) could be replenishable but ultimately something that – if they really wanted to – the U.S. and China could create themselves. But an NHS dataset cannot be replicated by the U.S. because they simply do not have a centralised national health service.
3. Data infrastructure and tacit knowledge. Perhaps more important than any singular dataset is the second order effect of simply being a country that knows how to build and use data, and having the data infrastructure already in place. This means having working pipelines and systems — but more than that, it means having the tacit knowledge the stems from having people who understand how to build data infrastructure. Estonia or Ukraine are cases in point.
Add these factors up and you realise it actually takes a lot for a data asset to be truly ‘leverageable’.
Where in the stack?
There is another question. Where in the AI development pipeline is the data feeding into, and what does this mean for the leverage that controlling access to that data generates?
Pre-training: the stage at which a large model is initially trained on massive volumes of data. This is the most likely part of the AI value chain that data would be feeding into, but it is also structurally the worst leverage position. Data contributed at pre-training becomes baked into the model’s weights which means once the training run is complete, that particular stock or flow of data can’t be revoked. That said, if it’s a replenishable dataset there is still (as argued) a strong incentive for continued partnerships. But otherwise, the owner’s bargaining position collapses the moment the run ends.
Fine-tuning: domain-specific datasets used to specialise a model create a periodic dependency, since each fine-tuning cycle requires fresh data. But cycles are not continuous, and a sufficiently capable base model may eventually reduce the need for further specialisation.
Retrieval-augmented generation (RAG): this is closer to the ideal. Rather than absorbing static knowledge in its weights, a model queries a live database on every inference call. The data owner retains custody, and the dependency is recreated on every query rather than established on a one-off training run. This position may well become more powerful as agentic AI takes off, and an AI agent must call live APIs to function.
Deployment data: when an AI agent operates inside your institution, it generates data about how it performs — where it succeeds, where it fails, where it needs human correction. That is exactly what labs need to improve their next model. Frontier labs will need this real-time feedback data in to improve their models in specific domains. So a government or company that hosts an AI agent could figure out how to generate something that the labs need.
All this is to say that one of the determinants of how much leverage data can give you goes beyond the nature of the dataset itself — but is to do with what part of the model training process you are selling it for. RAG and deployment data are more likely to generate a long-term chokepoint than pre-training or fine-tuning.
Case Studies
Ukraine: Drone Data
As outlined in an excellent article for Lawfare by Sam Winter-Levy and Jake Steckler, Ukraine’s decision to make millions of drone combat videos available to U.S. AI partners for training – but not for physical transfer – is the most instructive recent case of leveraging data because all the necessary features align. The data is continuously generated by an active conflict and depreciates rapidly: a model trained on 2023 footage is materially less useful against 2025 electronic warfare conditions, so partners cannot bank the asset and must keep engaging. Access is streamed rather than downloaded, preserving the tap rather than emptying the barrel. Because once a model trains on a static transfer, the owner has lost the lever, and Ukraine has structured the arrangement specifically to avoid that. And a dedicated centre within the Ministry of Defence provides a single institutional chokepoint that can update or revoke terms unilaterally. Both of the key features — replenishability and institutional control — are present.
The Protein Data Bank
The Protein Data Bank, whose carefully labelled protein structure data underpinned DeepMind’s AlphaFold breakthrough, is another useful example. What made it irreplaceable was that this was not something you can quickly curate or commission; it was the accumulated knowledge of a global scientific community. But that is also what would make repeating it – let alone doing it within the confines of a nation-state and convincing scientists that it would not be open source – incredibly difficult.
Indeed there is a serious tension here especially in the case of scientific data: one can only really convince scientists to contribute to and annotate this kind of data if it is to be an open dataset. And it will only be truly valuable if it is an international effort – thereby making this kind of thing difficult for a single nation-state to build as either a source of comparative advantage, or leverage in return for frontier access. Put simply: there is a real trade-off between control (can a middle power “own” a data asset?) and capability (is it actually useful?) for scientific data. The most useful scientific datasets are global ones that one nation does not control the taps to. For national AI strategies that talk of scientific datasets as potential strategic advantage, that tension needs to be contended with.
NHS Data
It’s the classic go do “data asset” referred to in UK AI policy docs. If properly centralised and curated, it has almost everything you would want: continuously generated data, legal custody sitting with a single institution, and a population large enough to be statistically meaningful across virtually any clinical question. The problem is that a frontier lab would extract enormous value from a single bulk training run — enough that losing access to future updates might not matter for years. Renewal only creates leverage if the model actually degrades without continued access, and that requires the relationship to be structured as live querying rather than a one-off transfer. The NHS could be a genuine chokepoint, but only if training happens on NHS infrastructure and the deal is built as an ongoing relationship – and of course if the UK controlled any IP from AI tools then spun out (one of the issues with the Palantir-NHS contract is that the UK has no control of the IP).
Whether a truly centralised NHS dataset is politically achievable is a separate question. The point is that, if it were to happen, it would need to be governed such that it would be a continuously replenishable source of leverage rather than something traded for one-off training run.
Dark Data: renewable but ungovernable
Unpublished findings, failed experiments, and negative results — the vast quantity of scientific work that gets done but never reaches a journal, either because it was inconclusive, because publishing null results is professionally unrewarding, or simply because it stayed on pen and paper — is increasingly cited as a potential training asset for AI.
This points to something more interesting than simply “building a dataset”: if you could restructure the incentives of an entire national scientific ecosystem to surface and publish this material, you would not be curating a static archive but turning your research base into a continuously generating source of training data. The asset would be the R&D ecosystem itself, not the dataset – which is a nice idea.
But in practice, dark data would probably fail on the single institutional chokepoint measure. There is no natural institutional ownership for this kind of data — it would be scattered across thousands of universities and labs with no obvious way to aggregate it and no shared incentive to do so.
And the deeper problem is normative: academic science runs on open-access norms, and any attempt to treat dark data as a proprietary national asset would face immediate resistance from the scientific community and international research partners. It is therefore a better argument for reforming how science gets published than for building strategic leverage.
Data For What?
All of this assumes, of course, that we are optimising for building datasets to leverage for frontier AI access.
But there are lots of other reasons why we might want to build AI datasets. Nations may want AI datasets, not to trade for access, but to give their national firms a head start in a given domain and thereby build comparative advantage. Indeed a government might commission the curation of a dataset to finetune its own national models. Equally, one might optimise not for the dataset itself as a leverage point, but building open datasets that drive a thriving open science ecosystem.
But quite frequently policy wonks refer to “leveraging data” or “build datasets” – only vaguely alluding to the idea that this would help create national advantage. Not explaining what the end goal is or what types of datasets would be most valuable. And this vagueness – both about types of data, and more importantly the reason for curating them in the first place – is a problem. If governments are to spend taxpayer money building datasets for AI, they need to be clear what they are doing it for: to further science, to accelerate domestic startups, or to use as a bargaining chip for access?
All are valid, but you can rarely have all at once. And the types of datasets that make the most sense for each purpose vary widely. It’s not always about building “chokepoints”, but if that’s the aim let’s get it right.
Data isn't the chokepoint... Example. Physics → Metrology → Measurement → Data → Information → Knowledge → Insights → Curiosity → (Repeat). Most "leverage data" strategies start at step four, this is the constant failing. Most people have zero clue what data actually is, or what it's for. This is not being arrogant this is being realistic. Because they arrive at the wrong layer. If you want intervention then you need to "Manufacture Engineer" it as such. Great article neverthless, loved the diagram.